運用面での成熟は、いくつかの新しい ツール を実装したからといって一晩で起こるものではありません。核となるのは、より良いソフトウェアを提供するためみんながコミュニケーションのサイロを壊せるよう一丸となって文化を変える努力です。個別にツールがあるだけでは十分ではありませんが、スピードと精度を向上させ、コラボレーションを促進するようなオートメーションを適用すれば、ツールが大きな利益をもたらすようになります。
環境に合ったDevOpsツールは、チームの規模やニーズに応じて大きく異なる場合があります。あなたのツールチェーンを構築する方法には正解はありません。現実に、まず私たちが学び、模倣しようとしたいくつかの最良のワークフローやツールはNetflix、Etsy、Dropboxなどの革新的なチームが社内に構築したものだということを告白しておきましょう。
このリストの目的は、ソフトウェア配信ライフサイクルの各段階で最も人気のあるツールをいくつか共有することです。その一部は社内でも使っています。自分のチームのために適切なツールを評価する際にご参考になることを願っています。
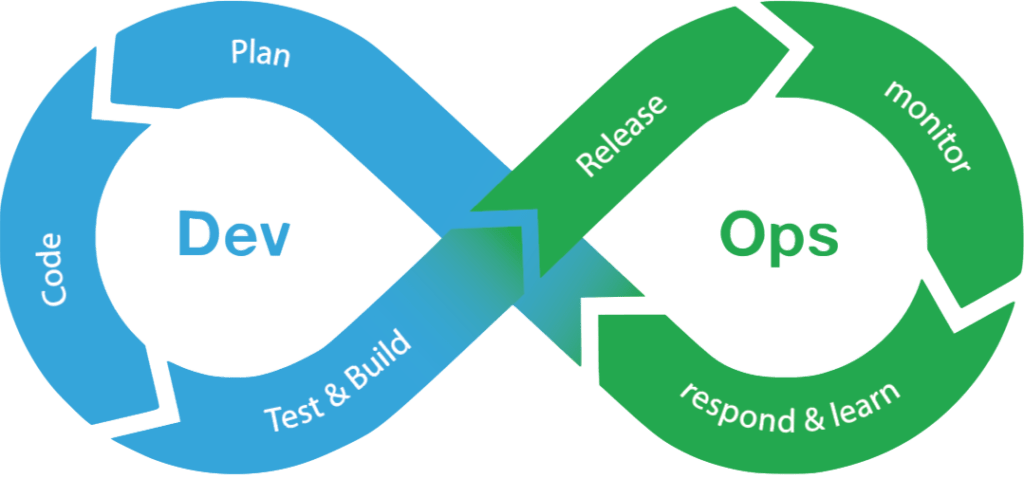
計画
何をどうビルドするのか
リリースのすべての単一の依存関係と作業を計画しておくというウォーターフォール型のアプローチはDevOpsに反します。代わりに、アジャイルアプローチでは、ソフトウェアを小さな塊で構築してテストし、顧客のフィードバックを反復することで、リスクを減らし、可視性を向上させることができます。それが私たちを含む多くのチームが約2〜4週間のスプリントでの私たちがリリースを繰り返している理由です。
チームが各スプリントの開始時にアイデアや計画を共有しているので、以前のスプリントの反省からのフィードバックを考慮に入れてチームとサービスが継続的に改善されるようにします。ツールは学習やアイデアを計画に集中させるのに役立ちます。ブレーンストーミングプロセスを開始する際は、顧客リサーチデータ、機能要求、およびバグレポートをそれぞれ対象となる個人を特定し、その人にマップできます。このプロセスでは、物理的またはデジタルの付箋を使用して、共通のテーマをまとめてグループ化し、バックログのユーザーストーリーを構築しやすくします。ユーザーストーリーを特定のペルソナにマッピングすることで、提供される顧客価値に重点を置くことができます。アイデア段階の後、プロジェクトのバーンダウンと毎日のスプリントの進行状況を追跡するツール内のタスクを整理し、優先順位を付けます。
私たちが使っているツール:Active Collab、Pivotal Tracker、VersionOne、Jira、Trello、StoriesOnBoardなど。
コード
いくつかのコードを書いた後に、ステージングに入る前に済ませる必要があることがいくつかあります。 コードをレビューして承認し、バージョンコントロールリポジトリのマスターブランチにマージし、必要に応じてローカルテストを実行します。
トップツール:Github、Bitbucket、Gerrit、GitLab
テストとビルド
今度はコードのビルド、テスト、およびリリースに関連するタスクの実行を自動化する時です。 ビルドが展開される前に、単体テスト、統合テスト、機能テスト、受入れテストなど、生産過程に完璧に押し込めることを確認するために、多数のテストを行う必要があります。 テストは、新しい変更が導入されたときに、コードベースの既存の部分が期待どおり確実に機能し続けるようにするための素晴らしい方法です。 新しいプルリクエストがあるときには自動的にテストを実行することが重要です。 これにより、手動による監視のために見落とされるエラーを最小限に抑え、信頼性の高いテストを実行するコストを削減し、早期にバグを面に出せます。
また、テストが完了したら、マスターの変更を自動的にピックアップし、依存関係のあるものをリポジトリからプルダウンして新しいパッケージを構築するなど、便利な機能を果たす多数の優れたオープンソースツールと有償ツールもあります。
トップツール:Jenkins、GoCD、Maven、CruiseControl、TravisCI、CircleCI
コンテナとスケジューラ
Dockerとコンテナの登場により、チームは新しい仮想化オペレーティングシステムをスピンアップすることなく、軽量で一貫した使い捨てのステージング&開発環境を簡単にプロビジョニングできます。
コンテナは、アプリケーションをパッケージ化する方法を標準化し、記憶容量と柔軟性を向上させ、変更をより簡単にすることを容易にします。 これにより、アプリケーションをどこでも実行することができます。 言い換えれば、物事は、あなたがラップトップで変更を加えたときとまったく同じように、魔法のようにプロダクションで行動します。
トップツール:Docker、Kubernetes、Mesos、Nomad
構成管理
構成管理を使用すると、インフラストラクチャの変更を追跡し、システム構成の単一ソースを維持できます。 バージョン管理とイメージの複製を簡単に実行できるツール、つまりシステム、クラウドインスタンス、コンテナなどのスナップショットを撮ることができるツールを探してください。 ここでの目標は、標準化された環境と一貫した製品パフォーマンスを保証することです。 構成管理は、変更に起因する問題の識別にも役立ち、さらに容量が必要な場合に既存のサーバーを自動的に再現することでオートスケーリングをシンプルにします。
トップツール:Chef、Ansible、Puppet、SaltStack
リリース
リリースの自動化
リリース自動化ツールを使用すると、本番環境に自動的にデプロイできます。 自動ロールバック、展開を開始する前にホストに成果物をコピーする機能などを備えた製品を選ぶべきであり、特に大規模な組織の場合は、サーバーインスタンスのスケールに合わせて、エージェントを簡単にインストールし、ファイアウォールを簡単に構成できるエージェントレスアーキテクチャが必要です。
テストに合格したものは、自動的にデプロイされることに注意してください。 ベストプラクティスは、最初に「カナリヤ」デプロイメントとしてインフラのサブセットに展開してみて、エラーが起きなければ全体に展開することです。
多くのチームでは、ボットを使って簡単なコマンドでデプロイするチャットベースのデプロイメントワークフローも使っているため、誰もが簡単にデプロイメントの活動を見たり、一緒に学習することができます。
トップツール:Bamboo、Puppet
デプロイメントを監視する
リリース用のダッシュボードとモニタをセットアップすると、リリースの進捗状況と要件のステータスをハイレベルで視覚化するのに役立ちます。 サービスが健全かどうか、導入前、導入中、導入後に異常があるかどうかを理解することも重要です。継続稼働している統合サーバー上で発生する重要なイベント、例えば失敗したビルドがあるとか、デプロイメントを中止またはロールバックするといった重要なイベントがリアルタイムで通知されること確認しておくことです。
トップツール:Datadog、Elastic Stack、PagerDuty
モニター
サーバーの監視
サーバーの監視では、インフラストラクチャレベルのビューが提供されます。 多くのチームでは、ログの統合機能を使い特定の問題をドリルダウンしています。 このタイプの監視をすると、メトリック(メモリ、CPU、システム負荷の平均など)を統合でき、サーバーの健康状態を常に把握でき、アプリケーションが影響を受ける前に(そしてお客様がそれに気がつく前に)に問題に対処できるようになります。
トップツール:Datadog、AWS Cloudwatch、Splunk、Nagios、Pingdom、Solarwinds、Sensu
アプリケーションパフォーマンスの監視
アプリケーションパフォーマンスの監視では、Webサイトなどのアプリケーションやビジネスサービスのパフォーマンスと可用性をコードレベルで把握できます。 これにより、パフォーマンスメトリックを迅速に理解し、サービスSLAを満たすことが容易になります。
トップツール:New Relic、Dynatrace、AppDynamics
対応と学習
インシデント解決
監視ツールは豊富なデータを提供しますが、リアルタイムで問題に対して正しい行動をとることができる適切な人物にルーティングされないならそのデータは無駄になります。ダウンタイムを最小限に抑えるには、問題が検出されたときに適切な情報が通知され、トリアージおよび優先順位付けに関する明確なプロセスが確立されていることが大事で、それらによってようやく効率的なコラボレーションと解決が可能になります。
1分に数千ドルのコストがかかるようなアプリケーションとパフォーマンスの問題が起きた場合、適切な対応を調整することはしばしば非常にストレスですが、混乱することはありません。火事の最中に、連絡先の住所録を取り出して、コンファレンスブリッジに適切な人を選ぶ方法を探すのに30分も無駄にするのは望ましくありません。
PagerDutyはエンドツーエンドのインシデント対応プロセスを自動化して、主要な顧客に影響を与えるインシデントや日々の運用上の問題の解決にかける時間を削減できます。 PagerDuty社内では、エンジニアリングチーム、サポートチーム、セキュリティチーム、エグゼクティブなどみんなが、自社製品を使い、ITやビジネスの中断への対応策を調整して準備しています。柔軟性を持って私たちはオンコールのリソースを管理したり、実行不可能なものを止めたり、関連するコンテキストを統合したり、適切な人やビジネスのステークホルダーを動員したり、自社が推奨するツールと協働で対応にしたりしています。自分が戦闘中に何をどうに見たいかを簡単に設計できるとしたら、あなたももっと安心できるでしょう。
私たちが使っているツール:PagerDuty、HipChat、Slack、Conferencing tools
学び、改善する
対応が終われば、インシデントはプロセスとシステムをより弾力性を持って改善する方法を理解する重要な学習機会を提供します。 DevOpssのCAMS(文化、オートメーション、測定、共有の頭文字)の支えによって、インシデント対応とシステム性能のメトリクスを理解し、継続的な改善の目標に向けて、成功と失敗を共有するオープンな対話を促進することが重要です。
ポストモーティム(事後検証)の手順を合理化でき、解決すべき事項に関するアクション項目の優先順位付けを目的にポストモーティム分析を実行できるソリューションを探してください。あなたはきっと製品の使用状況や顧客からのフィードバックを理解するのに役立つツールを使い、ビジネス目標と顧客経験のメトリクスに関連するサービスがどのくらい成功しているか測定したいと思うでしょう。より良い製品とより幸せな顧客のために、システムと機能の両方の改善を正確に計画して優先順位を付けられるよう、すべてが次のスプリントに組み込まれるのです。
私たちが使っているツール:PagerDuty、Looker、Pendo、SurveyMonkey
繰り返しますが、ツールに投資するだけでは、モノリシックアーキテクチャーからマイクロサービスアーキテクチャに移行することはできません。また、セルフサービスのデプロイメントを1日に何回も実行できるチームは幻のままになります。 しかし、適切なツールとプロセスで新しい文化へのシフトを強化することで、ソフトウェア配信を最適化し、継続的に改善し、それを担当するすべての人の間でシームレスなコラボレーションと信頼を実現することができます。
以上を参考に、あなたのための適切なツールを探究し、見つけることに成功してほしいです!全員参加の機運を最大限に高めるために社内で使用すべきツールや、DevOpsのベストプラクティスを加速する方法について詳しく知りたい場合は、これらのリソースをご覧ください。
 カテゴリー :ベストプラクティス
カテゴリー :ベストプラクティス

