PagerDuty の核となる部分の1つは、ユーザーにインシデント通知を送信することです。しかし、ただの通知ではなく適切なタイミングでの適切な通知である必要があり、すでにインシデントに対処しようとしているときにスマホをスパムマシン化させないようにする必要があります。2018年にはElixirを使って、PagerDutyの通知をすべてスケジュールするサービスを書き換えました。
この記事では、通知がどのように機能するのか、また、書き換えを成功させるためにErlang VM(別名BEAM)とElixirをどのように活用したのかを見てみましょう。
古代の歴史
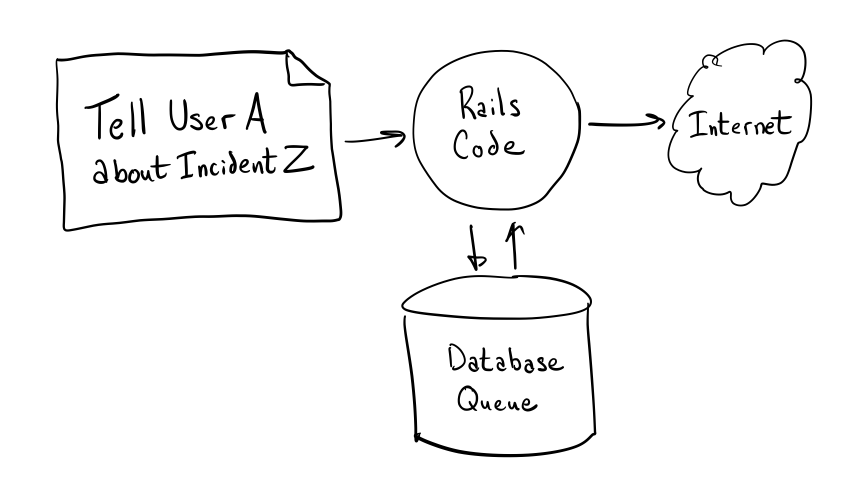
当初は、すべての通知はモノリシックなRailsアプリから直接送られていました。
2014年には、スケジューリング動作がScalaの新しいサービスに実装されました。Artemisです。当時のArtemisは斬新なもので、同期、マルチリージョン、永続的なキューを実現するために自作のCassandraでバックアップされたWorkQueueライブラリを使用していました(当時のKafkaはこれらのボックスをすべてチェックしていたわけではありません)。
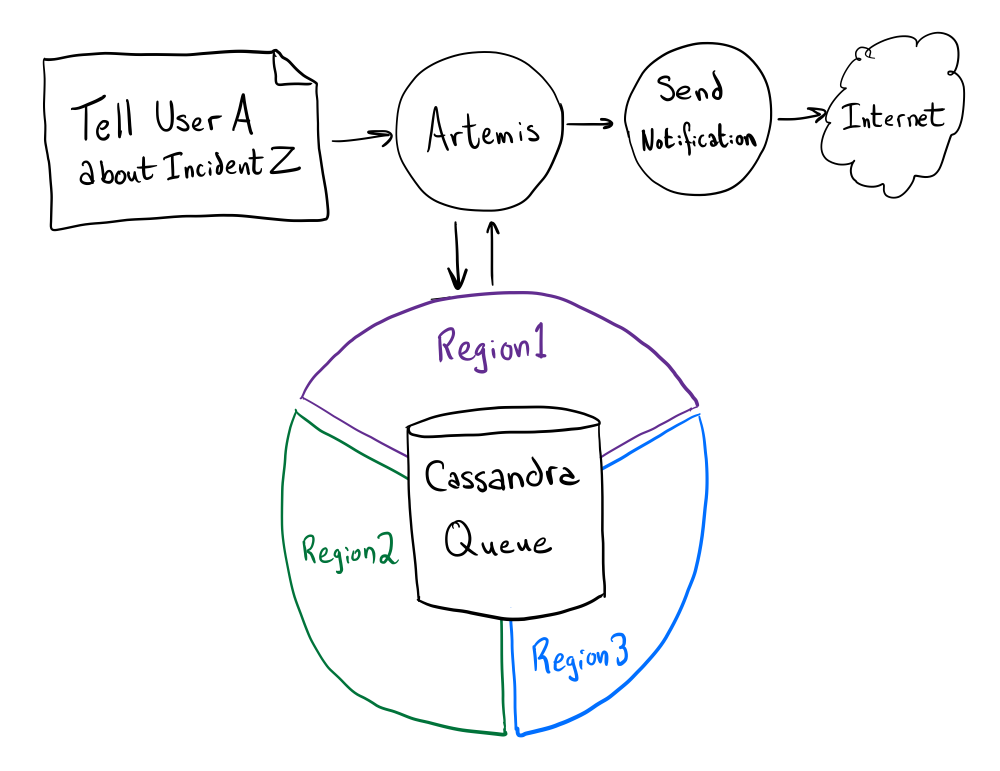
この抽象概念の上にあるArtemisは事実上ステートレスでした。キューをポーリングし、作業アイテムをロックし、作業を行い、ロックを解除し、忘れます。このきめ細かいロックは効果的で、どこにいてもアイテムの作業ができ、関係のない作業アイテムを同時に実行することができます。
最近の歴史
私たちは、システムのブラックボックスの動作(すなわち、その入力と出力)を見直し、Artemisの複雑さとインフラコストと対比させました。何かをしなければなりませんでした。私たちは、マイナーな改善作業か、大規模な改修か、あるいは完全な書き換えを行うかを検討しました。
完全書き換えの危険性を慎重に検討した結果、リスクを上回るメリットがあると判断し、進めることにしました。これは通常、リスクの高い提案と考えられていますが、Scala、WorkQueue、Cassandraの使用を止めたかったので、この状況ではうまくいきました。当社のエンジニアは、これらの技術が組織内で人気を失っていくにつれて(また、オリジナルのコード作成者が去っていくにつれて)、これらの技術に馴染みが薄くなってきていました。
Cassandraの3つのアンチパターンは以下の通りです。
- Cassandraをキューとして使用しない
- インターネットで同期レプリケーションはしない
- 非常に広い列は、Cassandraの水平方向のスケーリングをブロックする
私たちは3つすべてをやっていました。新しい技術スタックを使用し、基礎となるデータモデルを完全に変更しようとしていたので、完全な書き換えはより意味がありました。
当時、PagerDutyは新しいサービスのためにElixirを使い始めていました。ElixirはErlang VM(BEAM)上で動作するコンパイル言語で、ScalaがJVMにコンパイルするのとよく似ています。Elixir/Erlangランタイムは、独立した軽量なプロセスからなる全く異なるパラダイムをもたらします(1つのVMで10万個のプロセスは普通です)。Erlangは数値計算や共有メモリ計算にはあまり向いていませんが、非同期に行わなければならい多くのことがある場合には優れています。
通知スケジューリングの仕組み
PagerDuty では、カスタムのコンタクトメソッドと、それらのコンタクトメソッドをいつ使用するかを示す通知ルールを設定することができます。例えば、以下のようなものです。
- 携帯電話番号を追加する
- インシデントが割り当てられたときにすぐに電話をかける通知ルールを追加する
- インシデントがあなたに割り当てられてから5分後に電話をかける通知ルールを追加する(インシデントがまだ開いていて、あなたに割り当てられていて、それを受任していない場合)
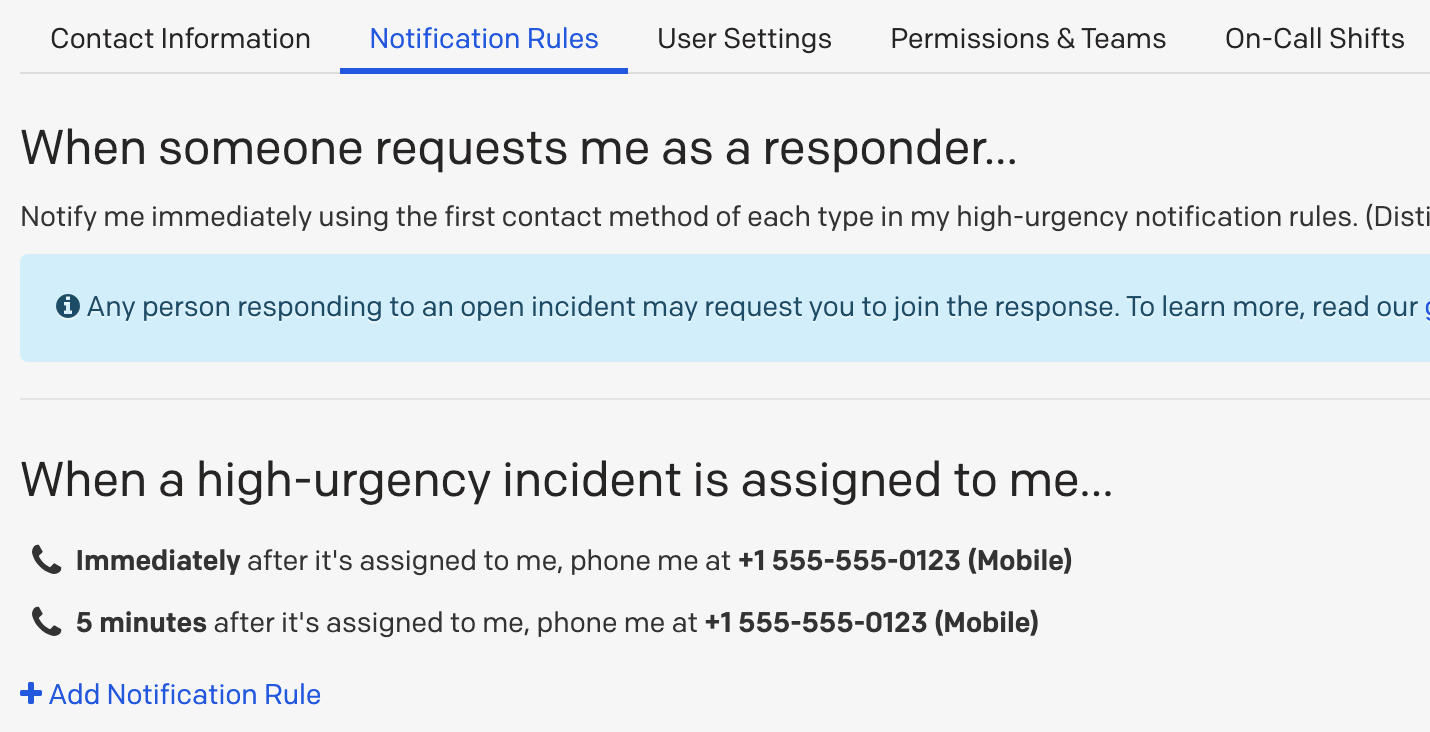
同じ電話番号でも、連絡方法が異なる(例えば、「電話 555-555-0123」と「SMS 555-555-0123」は別)ため、それぞれの連絡方法は別々に扱われます。緊急度の低いインシデントと緊急度の高いインシデントが混在することもありません。情報通知(「私が担当しているインシデントがエスカレーション、受任、解決されたらすぐに教えてください」)はこれらのルールと相互作用しますが、この例では関係ありません。
例えば、インシデント#1があなたに割り当てられたとします。あなたに知らせるために電話をしてみますが、あなたは出ないかもしれません。数秒後、別のインシデント(#2)があなたに割り当てられたとします。私たちはあなたに電話をかけたばかりなので、すぐにはそれを通知しません。私たちはこの動作を「ペーシング」と呼んでいます。これは、あなたがインシデントを解決しようとしているときに邪魔をしないためです。
ペーシングの間隔が切れたら、インシデント#2と、あなたがまだインシデント#1に割り当てられているという事実をお伝えします。あなたがその時も電話に出なかったとしましょう(シャワーを浴びていたのかもしれません)。
5分後、次の通知ルールが適用されます。しかし今回は、インシデント#1については今すぐに、インシデント#2については数秒後に通知する必要があることに気づきました。今回は、あなたに一度だけ電話をして、積極的に両方のことを伝えることにします。この動作を「バンドル化」と呼んでいます。
もしインシデントのどちらかが誰かに受任されたか、または解決された場合、私たちはそれらについてあなたに伝え続けることはありません。
まとめ:ハンドリングされていないインシデントについて連絡する間隔を管理するルールがあります。私たちは、合理的な範囲でできるだけ少ない通知を送るようにしながら、その都度発生しているすべてのことをお知らせするようにしています。
通知スケジューリングサービス
Notification Scheduling Service(別名NSS)を入力してください。この問題の美しいところは、それ自体が並列化に適しているということです。PagerDuty の各ユーザーへの通知は、お互いに全く相互作用しません。各ユーザーは島です。各ユーザーの小さな島の中にあっても、個々の連絡方法(例えば、「緊急度の高いインシデントの場合は+1-555-555-0123に電話してください」と「緊急度の低いインシデントの場合はMarvinDroidにプッシュ通知してください」)は、「このインシデントに割り当てられたユーザー」を各ユーザーのルールに従った連絡方法にマッピングする場合を除いて、他のユーザーとは相互作用しません。
私たちは各ユーザーをErlangプロセスとしてモデル化し、関連するUserChannelsを管理しています(これもErlangプロセスとしてモデル化されています)。これにより、新しい情報を素早く取り込むことができます(各インシデントの時間ルールごとに未来の日付の通知トリガーをキューに積みます)が、各UserChannelは自分のペースで状態を進化させることができます。インシデント#1についてユーザーAに伝える必要があることを知ると、ユーザーAのユーザープロセスにメッセージを送信します。そのユーザープロセスはユーザーの通知ルールを参照し、関連するすべてのUserChannelに、このインシデントについていつユーザーに知らせるべきかを伝えるメッセージを送信します。
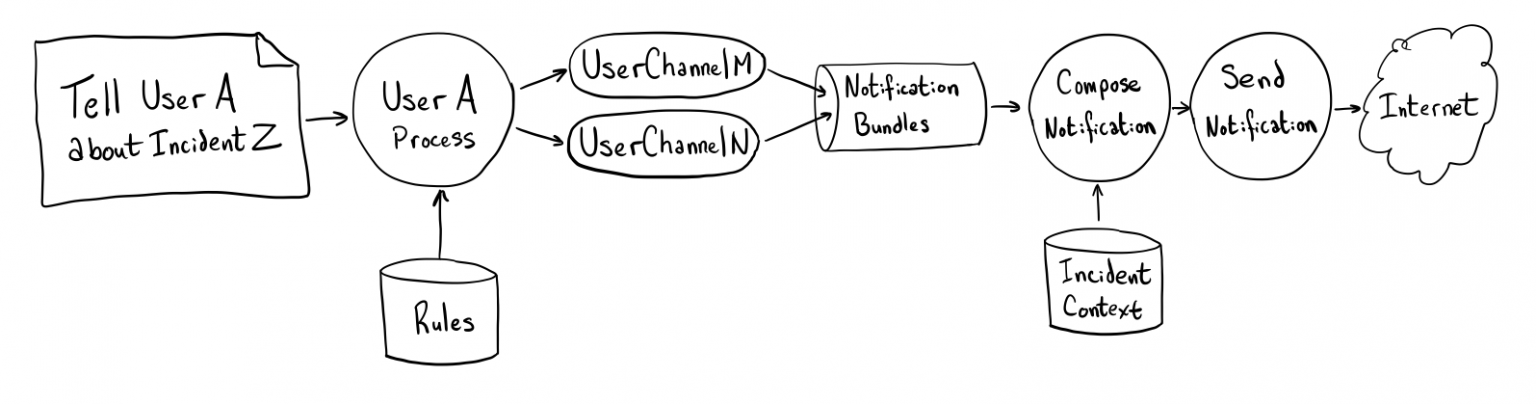
NotificationBundlesはNSSの第二段階でピックアップされ、あなたに送信する実際の通知内容を決定します。これには少し時間がかかりますが、これらのNotificationBundlesはすべて別々の連絡方法とユーザーに送信されるので、作業を並列化することができます。
PagerDutyは小さなシステムではありませんが、コンピュータ用語では、我々が扱うオープンインシデントの数は「ビッグデータ」ではありません。私たちは、この関連する状態のすべてをメモリに保存しているので、より速く行動できるようになっています。これは、状態のないArtemisのシステムとは正反対です。各ユーザーを Kafka パーティションに関連付け、与えられたパーティションを処理する NSS のインスタンスが最大でも1つ(通常は正確に1つ)あることを保証します。これにより、User と関連する UserChannels がシステム内でsingletonになるのは簡単です。粒度の粗いパーティションロックを使えば、プロセスが小さな作業をしようとするたびに同期をとる必要がなくなります。現在データを処理している部分を除いて、その特定のデータの変更を担当するシステムの部分はありません。ユーザーとUserChannelは、状態の変更とともにidempotency メタデータを維持し、クラッシュの回復や定期的なソフトウェアのデプロイを可能にします。
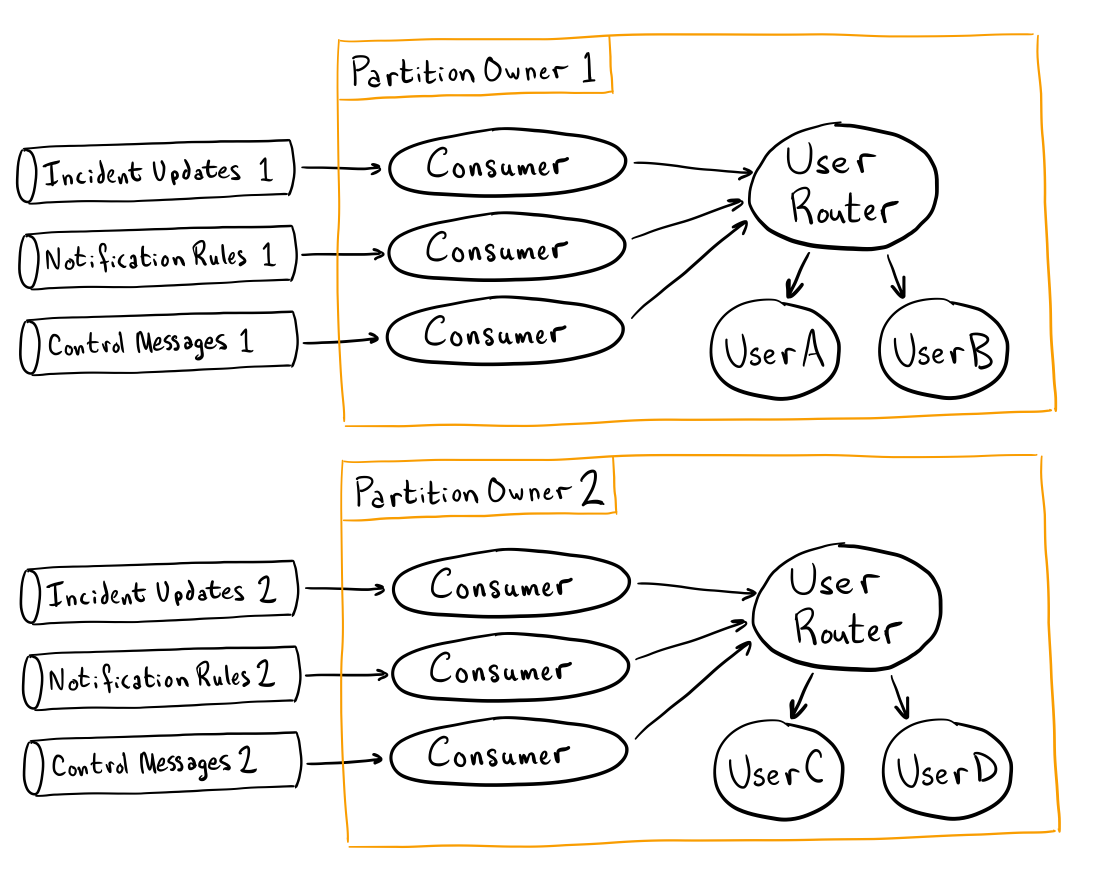
各ユーザーに独立したパーティションを与えるのは素晴らしいことですが、Kafka はパーティションの数に比較的制限があります(クラスタあたり約 50k)。その代わりに、Kafka駆動のアプリケーションでは通常のように、トラフィックをパーティションに分割します。異なるライフサイクルを持つ異なる種類のデータがあるため、「並列パーティション」を持つ複数のトピックを使用することになりました。これらのトピック間のメッセージは同期する必要はありませんが、特定のユーザーのすべてのトラフィックが同じパーティションセットに表示されるようにすることでメリットがあります。この例では、3 種類の受信メッセージがあります。
- インシデントの割り当て、状態の更新
- ユーザーの連絡方法と通知ルールの更新
- 下流システムからのフィードバック(例:「この電話は完了しました」など)
システム内のパーティションごとにパーティションオーナーを実行して、そのパーティションから3つのトピックを同時にconsumeする(例えばパーティション1のパーティションオーナーは、インシデント更新トピックのパーティション1、通知ルールトピックのパーティション1、制御メッセージのパーティション1のデータをconsumeして処理するように調整する)。
下の図では、ユーザーAとBのデータはすべてパーティション番号1のみで終了し、ユーザーCとDのデータはすべてパーティション番号2のみで終了します。
変更の成果
NSSが状態を維持することで、すべての実行中の作業を高速にアクセスできるメモリに保持することができます。ロックはパーティションレベルでのみ発生し、作業のピースごとに細かくロックするオーバーヘッドを回避します。独立した動作を管理するために軽量プロセスを使用することで、順序が重要なところでは一度に1つのことに集中し、順序が重要でないところではシステムが同時に多くのことを行うことができるようになります。この新しいインフラは、サイズは(計算とデータストレージの点で)10分の1、ラグタイムは半分、スループットは10倍です(追加の水平方向のスケーリングのための余地は十分にあります)。2019年1月以来、私たちは通知トラフィックの100%をそれを介して実行しています。
この記事は、私たちが何をしたのか、そしてElixirで何が可能なのかの表面をかいつまんだだけです。このような背景を踏まえて、第2弾をお届けしたいと思っています。
本記事は米国PagerDuty社のサイトで公開されているものをDigitalStacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

