チームにこう伝えました。「SignalFxで重要なイベントが進行中の場合は通知してほしい」。しかし、システム監視の会社のCTOであるにもかかわらず、進行中のインシデントや潜在的な問題を常に把握するために、適切なアラートを作成することは思ったよりも困難でした。
どうして?
クラウドとオープンソースの登場により、ソフトウェアをより迅速に構築できるようになりましたが、今日の環境は次のようなさまざまな理由から、監視と管理が非常に複雑になっています。
- 監視するインスタンス数の爆発(ホスト、コンテナ、関数)
- サービスはまれに「正常動作」というメトリックを発したり、常に変化したりする
- マイクロサービス構成のため、個別に監視する必要があるサービスの量が増えている
私たちの経験による結論は、誤検知や繰り返される警告の嵐です。アラート疲れはチームがリアルタイムで問題を見つけて解決する能力を妨げるだけでなく、長時間対処されないとチームの士気を破壊し、本来予防可能なシステムダウンをもたらします。
アラート疲れを軽減するための戦略
アラート疲れを軽減することは、自らの焦点を広げることから始まります。きめ細かなメトリックの測定は、トラブルシューティングやフォレンジック分析には非常に役立ちますが、最も効果的なアラートは、アプリケーションの健全性に関する高レベルのインジケーターを構成するシグナルの組み合わせに依存します。特に、次の点を考慮する必要があります。
個々のインスタンスではなく、全体を監視
環境内の個々のコンポーネントのステータスを警告するのではなく、サービスごとまたはグループごとの健全性インジケーターを定義してモニターします。たとえば、サービスインスタンス間のAPI呼び出しの99%が要している遅延時間、ノードの特定クラスタの平均CPU使用率、コンテナのグループのAPIエラーの合計などを追跡します。
1436台のホストのシステムメトリックを集約
固定の閾値よりもパターンと傾向に関する警告
変化する環境に適応できるアルゴリズムで生成された閾値を使用する。分散システムはしばしばミステリアスな方法で動作するため、アラートが発生する前に正しいCPU使用率やAPIエラーの数を判断することは非常に困難です。

単純セッション数と週をまたいだ変化
定期的なパターン(たとえば平日の高トラフィック)や予測的なアラート(次のN日以内にクラスタがディスク領域を使い切るのを警告する)によって、システムの通常の動作と対応を必要とするものを区別できます。
グラフが示す容量のメトリックの傾向
アプリケーションのパフォーマンスの全体的な尺度の定義
さまざまなマイクロサービスのメトリックを組み合わせて、より高いレベルのシグナルとアラートを導き出す。たとえば、ログインユーザーあたりのページ読み込みの数と、API呼び出しの合計に対するAPIエラーの割合です。あるお客様は、すべてのマイクロサービスのメトリックを組み合わせて、デプロイしたバージョンのパフォーマンスが全体的に改善されたかどうかを示すヘルススコアを作成しています。
ソーシャルシグナルの測定
SignalFxでこれらのテクニックをすべて使用していたにもかかわらず、まだ誤検知のアラートが多すぎました。次の点に注意しました。
- 私はエンジニアリングリーダーなので、サービスオーナーやオンコールエンジニアのように細かいアラートを必要としません。アラートのサブセットをフォローするのは、警告なしにリストがすぐに古くなるため実用的ではありません
- 私たちはPagerDutyを使用していますが、私が常にオンコールのエスカレーションパスにいるとは限りません
- 私はSignalFxのステータスページのようなソースを見ることでマイナーな問題をフィルターすることができますが、その代りにインシデント対応に積極的に関わりたくても、アラートが届くのが遅すぎて気付くのが問題が大きくなった後だったということになりかねない
では、他にどのようなシグナルを検出できるでしょうか? 我々SignalFxは#outageという名前のインシデントについてのSlackのチャンネルを作っていました。また、このチャネルは、PagerDutyから重要なアラート通知を受け取って、議論の内容を保存します。運用してみると、重大な問題には多くのユーザーがSlackでコラボレーションし、PagerDutyを介してエスカレーションしているという事実を知ったので、私は#outageで人間の活動に関するメトリクスを収集することにしました。結果は次のようになりました。
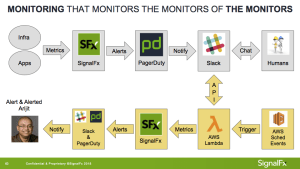
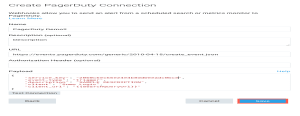
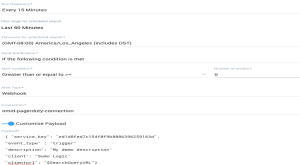
私はAWS Lambdaセットを使ってメッセージを照会し分類し(例えば人間かボットか)、それをSignalFxに公開しました。次に、3人以上の人が#outageで5分以上タイピングしていると私に通知する検出システムを作りました。アラートはPagerDuty経由で私の電話に送信され、Slackに直接メッセージが送信されます。
進行中の潜在的な機能停止を警告する
これは驚くほどうまくいきました。誤検知が全くなくはありませんが、その数はほぼゼロになり、関心の高いインシデントは全て通知されました。興味深いことに、いくつかの潜在的なインシデントについてアクティブなアラートとしてではなく通知を受けましたが、エンジニアはいつものサービス観察の中でそれを発見していました。
ハードウェアとソフトウェアの監視は停止しない
最初は、アプリケーションとインフラのメトリクスだけを使用して「完全な」アラートが作成できないことに失望しましたが、これは素朴な期待だったかもしれません。正確なアラートを作成するにはシステム環境を理解するだけでなく、組織がどのようにインシデントに対応するかを知ることも必要です。
私の問題の解決には人間の行動を測定することで十分でしたが、今日のツールの多くが相互運用性とデータ非依存を志向していることを考えると、モニタリングに組み込む可能性のあるシグナルはたくさんあります。
インシデント管理と問題検出を統合する
リアルタイムのビジネスはリアルタイムの運用インテリジェンスを必要とし、今日のテクノロジーは従来の監視ツールで処理できる量よりもはるかに多くのデータを送信します。SignalFxは環境内の各コンポーネントからのストリーミングメトリックを収集し、数秒で分析とアラートを提供するため、問題が顧客に影響を及ぼす前にそれを見つけて解決することができます。
SignalFxとPagerDutyを使用すると、SignalFxでアラートがトリガーされたときにPagerDutyでインシデントを自動的に開くことができます。アラートに応じて異なるエスカレーションポリシーにマップし、正常に戻ったときに解決されたインシデントを自動的にマークします。
SignalFxは、組織が重要なシグナルをリアルタイムにあらゆる規模で監視するのを助け、かつてないほど迅速に革新することができるとの自信を持っています。
Arijit MukherjiはSignalFxのCTOで、システムの監視に情熱を傾けています。Facebookのメトリクスソリューション(ODS)のオリジナル開発者の一人であり、その後もFacebookのネットワーキングツール、データビジュアライゼーション、その他のインフラ監視ソフトウェアの開発を管理しました。10年以上にわたり監視の領域に重点を置いていましたが、20年以上にわたる彼の多様なキャリアは、IPテレフォニー、VoIP会議、ネットワーク仮想化にも及んでいます。
本記事は米国PagerDuty社のサイトで公開されているものを日本語訳したものです。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

