一見すると、機械学習を継続的デリバリー(Continuous Delivery)に適用するのは、ハンマーでピーナッツを割るように聞こえるかもしれません。 つまり、デプロイメントの自動化は実際どれだけ難しいのでしょうか?
調べた結果、それは私たちが考えるよりも複雑です。
新しいデプロイメントをプロダクションに移すと、通常2つの結果になります。
- サービスは起動し、すべてがOKだと思う。
- サービスは起動せず、何もかもが壊れてる。
現実には、上の2つの点は、組織の95%がデプロイメントの成功を測る方法(上=良い、下=悪い)を表しています。 幸せなPagerDutyのお客様は、2番目のシナリオ(携帯電話にアラートとインシデントの嵐が届く状況)はよくご存じです。 しかし、シナリオ1は、誤解を招く可能性があります。サービスが動いているからといって自動的に健全性、性能、品質がOKだという証拠ではないからです。
手動でデプロイメントのヘルスチェックをする短所
Harness(訳注:Continuous Delivery-as-a-Service プラットフォームのサービス提供会社)で最初の25人の顧客から私たちが学んだ1つは、大部分の組織では一般的に3〜5人のエンジニアがいて、手動で実稼働展開を確認するのに1時間以上かかるということです。例えば当社の顧客のBuild.comは5-6人のチームリーダーがNew RelicとSumo Logicのデータを手動で分析するのに1時間かかっていました。これは通常、複数のコンソール/ブラウザウィンドウを開き、bashスクリプト、アプリケーションパフォーマンス監視、ログ分析ツール間でコンテキストを切り替えることを意味します。
人間の脳は短期記憶を使う際は8-10項目しか集中できず、様々なシステムからのすべてのデータが集中していることを考えると、2018年の人間は非常に簡単にミスをします。数十万回の時系列メトリックと、展開後に数百万回のログエントリーがあることを考えれば、 手作業による分析とヘルスチェックは難しい問題です。
AIと機械学習がヘルスチェックを支援するようにする
Harnessでは、ソフトウェアアーチファクトのプロダクションへのデプロイメントを自動化するだけではありません。 AIや機械学習を使ってヘルスチェックを自動化します。 私たちはこのContinuous Verification(継続的検証)と呼んでいます。
主に隠れマルコフモデル、記号集約表現(訳注:Symbolic Aggregate Representation。いわゆるSAX)、k-平均法クラスタリング、およびいくつかのニューラルネットなどの教師なし機械学習アルゴリズムを使用して、APM(アプリケーション性能指標値)とログデータから異常や性能低下の検出を自動化します。
Harnessは、新しいソフトウェアアーチファクトを数秒で展開して、任意のAPMツールまたはLogツールに接続し、パフォーマンス(応答時間/スループット)と品質パースペクティブ(エラー/例外/イベント)から、アプリケーションの動作モデルを自動的に生成できます。
Harnessはこれらのモデルを以前のデプロイメントと比較し、新しい異常や性能低下を即座に示します。 人間が処理や分析をするのに要する時間に比べ、機械学習アルゴリズムでは数秒しかかかりません。
たとえば、以下のスクリーンショットはAppDynamicsのAPMデータをHarnessで検証した結果です。

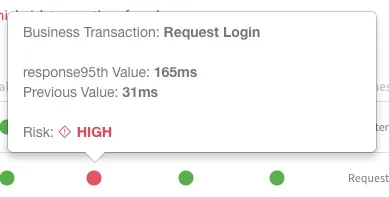
上記の画像では、Harnessが展開後に2つのビジネストランザクションがパフォーマンス低下を示していることが分かりました。 以下の図では、「Request Login」という1つのトランザクションで、応答時間が31msから165msに増加したことを示しています。 この分析はすべてAI と機械学習で自動化されています。
SplunkからのアプリケーションログについてHarnessが検出したエラー/例外の異常の別の例を次に示します。
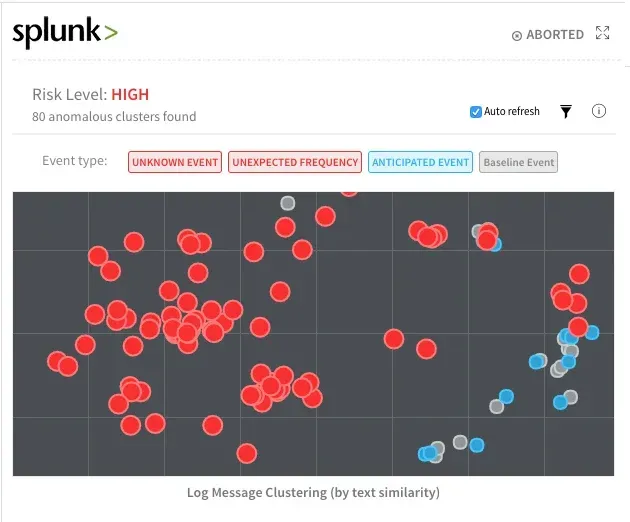
赤い点は、デプロイ後からアプリケーションログに入るようになった新しいエラーを示します。 灰色と青色の点は、すべてのデプロイで通常観察されるベースラインのイベントまたはエラー/例外を表します。
ハーネスは、k-平均法クラスタリングといくつかのJacardおよびコサイン距離演算(訳注:ふつう、集合の類似度を示す)を使用して、これらのビジュアルを生成します。 任意の点をクリックすると、イベントのスタックトレースと根本的な原因も表示されます。
AI / 機械学習インテリジェンスによるロールバックの自動化
Harnessは、Continuous Verificationのインテリジェンスを使用して、デプロイメントのロールバックを自動化することもできます。 Harnessは、Dev / DevOpsチームがより速く展開できるようにしながら、新しい異常や性能低下に遭遇するたびにロールバックできるようにするセーフティネットと考えてください。
今後のPagerDutyのHarnessサポートにより、各組織はPagerDutyを通知チャンネルとして、また検証ソースとして使用することができます。 たとえば、Harnessはデプロイの前にPagerDutyに対して、運用中に発生しているアクティブなインシデントがあるかどうかを確認するクエリを送信できます。Dev / DevOpsチームが最後に望むのは、本番環境に展開することです。
まとめると、Harnessは、 継続デリバリー・サービス( Continuous Delivery as-a-Service )を提供することで、各組織が本番環境でエンドユーザーへのソフトウェアの展開と配信を自動化することを支援します。私たちは、顧客が何かを壊すことなく迅速に動けるよう支援します。
Steve BurtonはHarness.ioのCI / CD DevOps Evangelistです。 Harnessに入る前は、AppDynamics、Moogsoft、GlassdoorでGeekをやっていました。 彼は2004年にSapientでJava開発者としてキャリアをスタートしました。 テクノロジーで遊んでいないときは、通常はF1を見たり、インターネットで車を研究したりしています。
本記事は米国PagerDuty社のサイトで公開されているものを日本語訳したものです。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

