3年前、私は 新興スタートアップだったPagerDutyにエンジニアリングマネージャーとして参加しました。 当社は2013年にシリーズAの資金を受けて超成長モードにあり、あらゆる分野で積極採用を進めていましたが、エンジニアリングチームは当時30人以下でした。急成長企業が直面している構造的課題の解決に、私は大きな魅力を感じました。エンジニアリングが100人のDutonian(注:Star Wars: The Old Republicに登場する)の群に増えつつある今、これまでの変化を振り返り、今後に反映させようと思います。
組織構造の進化は魅力的なプロセスです。それはたくさんの間違い、行き止まり、車輪の再発明みたいなことでいっぱいです。うまくいけば、エンジニアリング組織をカバーする文献はたくさんあります。その多くは、賛否両論の抽象的なリストみたいなもので沸騰しています。また企業が採用したプロセスを自画自賛するようなブログ記事も投稿されています。私は別のアプローチをとって、エンジニアリングチームが構造を進化させる試みを繰り返し、それに伴って起こった誤解や学びのすべてを包括して、そこから歴史的な教訓を得たいと思います。
注:イベントや詳細の一部は、ストーリーを分かりやすくするため省略しています。このブログをブックマークしておくと、新しいコンテンツを見ることができます。
昔はサイロ化した組織でした
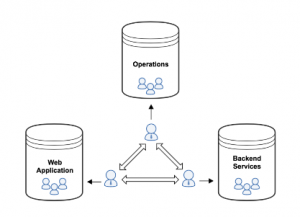
2014年初頭のPagerDutyは次のように見えました。
-
エンジニアリング組織は、サンフランシスコ(SF)とトロントのオフィスに分かれていました。
-
運用チームは、インフラストラクチャの自動化、セキュリティ、およびパーシステンス(SFのみ)を担当しました。
-
WebアプリケーションチームはPagerDutyの顧客に
見えるの部分を担当し(SFのみ)、主にRuby on RailsとMySQLで
開発をしていました。
-
バックエンドサービスグループは、信頼性の高いデータ収集と通知配信を担当し(SFとトロントにチームが分割配置されていました)、主にScalaとCassandraで開発をしていました。
-
DevOpsには部分的な遵守事項しか明文化されていませんでした:
運用チームは、インフラストラクチャ監視アラートのオンコールを担当し、他のチームは導入したコードのオンコールを担当していました。
エンジニアリングが非常に短期間に少人数からいくつかの分散したチームへと成長する中で、製品開発プロセスは未成熟なままでした。スタンドアップとスプリントを使い表面的には敏捷に動いているように見えていたにもかかわらず、基本的にウォーターフォールモデルを使っていました。リーダーシップは、作業すべきプロジェクトを定義し、個々のエンジニアをそれらのプロジェクトに割り当て、目標とする納期を定義しました。予想通り予定はあまり守れずプロジェクトのスプレッドシートは壊滅的な状態になりついには使われなくなりました。
事態はうまく進むように見えませんでした。プロダクトマネージャーは、開発中に発生する可能性のある疑問を予期して詰め込んだ長い機能設計仕様書を作って新しいプロジェクトを開始しました。プロダクトとエンジニアリングは実際には開発中にはあまりやりとりをしないのに、です。この仕様では、Webアプリケーションとバックエンドサービスチームに提示され、ユーザーチームとバックエンドの側面を個別に担当しました。新しいインフラストラクチャのリクエストは、数週間前に運用チームに提出する必要がありました。
こうした努力の数々をすべて一貫した機能リリースに統合することは悪夢でした。我々は不完全なインフラしかなかったり(またはまったくインフラが用意されていなかったり)、バグ、機能ギャップ(各チームが、きっと他のチームがそれをやっていると思いこんでたのです)、エンジニアと製品の両方のオーナーシップやエンパワーメント、日数不足、組織のサイロ化や不整合がありました。期限通りに出したいという欲が、リスクテイクを減らすことにつながりました。私たちは実装においてより慎重になり、製品の仕様を調整することに嫌気しました。
この部門の構造と開発プロセスの組み合わせは、その年のエンジニアリング内の他のすべての議論の最前線にサイロの話題を押し上げました。 おーい僕らはサイロに落ちているんじゃないの?と。
-
Webアプリケーションvsバックエンドサービス 2つのグループの間 には緊張がありました。 どちらも他のグループが取り組んでいたことをちゃんと理解しておらず、不満でした。
-
Ruby vs Scala 上記と似ていますが、特定の言語を中心に多くの「自転車置き場」(注:本当に必要か、どこに作るべきかをきちんと検討せずに作られたものを指す)やアイデンティティを構築していました。
-
オペレーションvs開発チーム。両方とも開発チームがすべてのサーバープロビジョニングのボトルネックとなっていることに不満を抱いていました。オペレーションは迫りくる締め切りに大きなプレッシャーを経験していました。
-
サンフランシスコvsトロント。 地理的に2つの場所に分かれたエンジニアの間で、同じ場所にあるエンジニアはまとまり、はっきりとした「彼らと私たち」の雰囲気が生まれました。 両陣営は何かと相手に不満を募らせました。
責任の集合を厳密に定義すればチーム間の機能的な連携に多くの余地を残すことはありませんでした。 私たちは、「ワーキンググループ」という概念を試してみたこともあります。小規模で一時的で多様なチームが責任範囲と日程が明確な横断的なプロジェクトに取り組むことを目的として、既存のチームからメンバーを編成しました。こうした取り組みは、プライマリチームを不安定化させて混乱を招いてしまったので、実験は中止されました。
でもみんなで協力してより高い整合性と予測可能性を顧客に提供することが一番大事なことでした。みんながサイロ化に悩んでいたので、解決しなければならなかったのです。私たちはなんとかやり遂げました。
マトリックス化した組織に
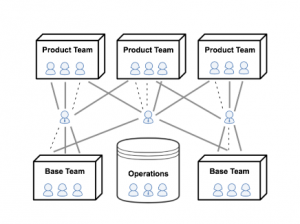
2015年の初めには、物事の状態への不満やアジャイル・メソドロジへの関心の高まりが重大になり、部門別に同様が生じました。特定の製品の方向性に合わせていくつかの新しいチームが結成されました。彼らはScrumプロセスに従い、Webアプリケーションとバックエンドサービスチームのエンジニア、製品所有者、Scrumマスター、UXデザイナーで構成されていました。
前年度の製品進捗状況が理想的ではなかったことを考え、新しいチームは製品提供のために最適化されていました。新しい機能の導入に100%時間を費やすことができるように、メンテナンス作業はバックエンドサービスチームに委任されました。これらはKanbanの方法論を採用し、「ベースチーム」として知られるようになり、プロダクト内のすべてのオンコールの責任を含め、すべてのサービスのオーナーシップを取りました。さらに、製品チームに供給された基本チームは、製品作業の増加に伴い、エンジニアが一方から他方に移行しました。
これらは明らかに大きな変化でした。個々のエンジニアへのチームシャッフルの影響を最小限に抑えるため(また、リモートレポートを処理することをやめるため)、レポート関係には触れませんでした。これはもちろん、皆さんの人生を驚異的に複雑にしました。なぜなら、マトリックス型の組織という二重のレポート構造を持っていたからです!多くのエンジニアは、直属のスーパーバイザーに割り当てられていないチームに所属し、マネージャーは、「人事マネージャー」(人員を管理。他のチームに所属する人も含みます)と「機能マネージャー」になりました(チームを管理。一部のエンジニアは別の人にも報告をしていました)。
良かった点は、古いサイロがほとんど壊されたことです。それが復活することはありませんでした。バックエンドサービスエンジニアと緊密に連携するWebアプリケーションエンジニアは、互いの違いを認識しながら、共通の目標に向かって進むことができました。もっとも、ほとんどのチームは地理的にも分散していたため、2つのオフィスを統合するのを不思議に思っていましたが。
悪いニュースは、新たな問題が発生したことでした。
-
テクニカルメンテナンスに関係するチームを結集することは非常に困難でした。ベースチームは、長期のロードマップを形成し、すべてのプロダクションサービスの運用上のオーナーシップをとる羽目になりました。
-
フィーダーモデルが各チームの結束に非常に大きな影響を与えました。チームの構成を何度も変えていくことは、士気にはあまり良いことではないことが分かりました。
-
二重のレポート構造はとても非効率でした。直接のレポートでは日常的な活動が見えず、人事マネージャーと機能マネージャー間ではコミュニケーションのオーバヘッドが起き、責任に関して混乱がありました。
-
私たちは、敏捷性よりもむしろアジャイルプロセスを採用しました。Scrumは、過剰な仕様、統合、製品のオーナーの関与を確かに助けました。しかし、ソフトウェア配信に対する当社のアプローチは変わらず、機能リリースは依然として価値があるかどうか怪しいという大きな問題があるものでした。
-
より多くのチームがオペレーションの人々に多くの負荷をかけました。インフラストラクチャの要求が頻繁になり、新しいサービスごとにオンコールの責任が追加されるため、このアプローチは拡張されませんでした。
すべてのことを考慮すると、私たちはまだ1年前よりずっと良い形になっています。
しかし、まだまだ道のりはまだまだありました。
アジャイル組織
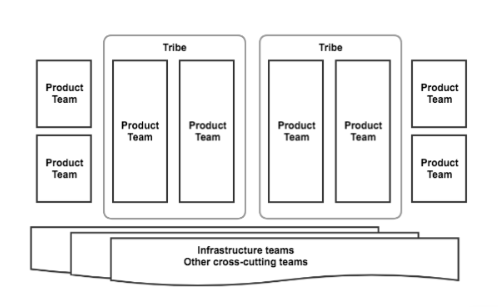
新しい組織体系で1年間生活した後、私たちはかなりの数の学習を蓄積しました。 アジャイルはうまくいっていましたが、十分な作業はしていませんでした。DevOpsはうまくいっていましたが、十分に機能していなかったので、マトリックス管理はそれほど良くありませんでした。
2016年の早い段階で、我々は再び再編した。 「垂直」製品スクラムチームは現在、製品の特定の部分を担当していました。 「水平」チームは、製品やインフラストラクチャの問題を横断する責任があり、ベストプラクティスを設定し、他のチームが速やかに動くことを可能にしました。 プロダクトデリバリーチームは、ロードマップ、要件定義、実装、デプロイメント、運用中のコードとインフラストラクチャ(!)の保守を所有していました。 私たちは真の開発者を採用しました.Ops「あなたはそれをコードします、あなたはそれを所有しています」アプローチ。
これは以前の懸念をどのように解決しましたか?
-
メンテナンスチームはこれ以上ありません。各チームは製品やインフラストラクチャの一部を所有し、迅速に移行し、革新する権限を与えられました。
-
フィーダーチームはこれ以上ありません。特定のチームに対して人員が開かれました。
-
もう二重報告はありません!組織として、遠隔のエンジニアの採用と管理をより快適にしました。物理的な距離がもはや障害ではなくなったので、私たちはマネージャーを点線関係のないチームに割り当てることができました。
-
私たちは物事を終わらせることに集中しています。 GSD(Get Sh * t Done)のマントラは、チームが実用的で生産的で機敏なデリバリーマシンに成長するために、過剰仕様化とオーバーエンジニアリングのイントロスペクトと遺産を捨てるようにチームに挑戦し、私たちの集団意識に浸透しています。
-
セルフサービスで成長が可能。オペレーションチームは、あらゆる種類のインフラストラクチャニーズに対応できるように、魅力的なChatOpsツールを提供するなど、製品配信チームに力を与えるために多くの作業を行いました。これはDevOpsを徹底的に採用し、インフラストラクチャのアラートをOpsから、実際のホスト(問題をより速く解決できる人)を持つ関連チームに移動するための鍵でした。
GSDの主題はもう少し詳しく調べる価値があります。練習を通して、私たちは、チームの自律性、発明よりも革新的なアイデア、そして実現する解決策ではなく解決するための問題をビジネスにもたらします。顧客にとって何がベストかを知っているという考えを放棄するのは容易ではありません。実行可能な最小限の製品を提供し、開発サイクル中に即座にフィードバックを取り込み、それを組み込むことに重点を置いたのが、レーザーの焦点でした。迅速に反復し、価値を最大化し、金めっきを最小限に抑え、数ヶ月から数日または数週間の間にプロトタイプを顧客の手に渡す時間を短縮することができました。言い換えれば、「アジャイルプロセスに従う」組織から実際のアジャイル組織に変化しました。
製品納品チームの数が増えるにつれて、興味深い現象が発生しました。いわゆる「部族」(Spotifyのチームモデルに対するハットチップ)、つまり共通の機能や共通の使命でチームのグループが出現しました。これらの取り決めにより、共有された所有権、知識の共有、ロードマップの共有(個々のチームのバックログとは別)、共有されたビジョンなどの利点がもたらされました。部族組織は私たちがまだ実験しているものです。部族との習得についての今後の更新についてお楽しみください。
私たちはこの構造で16ヶ月稼働しています。確かにチームと関連するオーナーシップラインは、会社が急速に成長し続けるにつれて進化します。同時に、正しいことがどのように見えるかを知るために、間違ったことを十分に行ったことは明らかです。
学んだ教訓
私が早期に決定したいくつかの決定と、組織が耐え忍んだ厄介な中間的な状態のいくつかに戻って考えると、私は頭の中で自分自身を叩きつけ、 明らかに優れた終わりの状態。 もちろん、現実は決して簡単ではありません。その決定は当時の国家、優先順位、国民、そして私たちの課題の関数でした。 あなたは自分の挑戦のいくつかを認識しているかもしれません。その場合、あなたは私たちの経験から何かを取り除くことができると願っています。
私がそれを何度もやり直さなければならない場合、これは私が私と一緒に持ってくる学習です。
-
チーム間の依存関係を最小限に抑えます。 依存関係は、ブロック、バグ、誤解、悪い気持ちにつながります。 チームが他の人たちを待つことなく提供できるようにすると、生産性が大幅に向上します。
-
チーム構成の変更を最小限に抑えます。 ビジネスの現実は、時折、リソースをある場所から別の場所に移す必要があることを指示しています。 チームの士気と生産性に重大な影響を与える可能性があるため、人を動かす前に長く考えてください。
-
チームの所有権と責任を過度に処罰しないでください。 ここでの柔軟性は、長期的な勝利につながります。 チームに自分の問題を解決させるよう促し、前の2つの点で問題が少なくなります。
-
継続的な学習と実験を恐れないでください。 これはコード、プロセス、組織といったすべてに適用されます。 同じことを何度も何度もやり続けると、1つは良くなりません。
-
アジャイルプロセスは素晴らしいです。アジャイル・カルチャーが優れています。スタンドアップとスプリントレビューは、自分自身で大きな価値をもたらすわけではありません。実行可能な最小限の製品、迅速なフィードバックループ、およびコラボレーションに焦点を当てることは、文化的な変化を必要としますが、提供される顧客価値を最大化します。
-
コードの運用上の所有権はチームと一緒に存続する必要があります。システムの信頼性、コード品質、および組織のスケーラビリティのバランスをとるための最良の方法です。
-
クロスファンクショナル、フルスタックのチームが製品の配送に最適です。これは、上記の依存性の最小化ポイントと非常によく似ています。各チームは、外部の専門家やプロジェクトのハンドオーバーを必要とせずに、要件の収集から展開に移行できる必要があります。スペシャリストチームには場所がありますが、以前に議論された「水平」チームの領域ではより多くのものがあります。
-
どのような環境でも動作できるジェネラリストを雇う。チームメイトは、技術と技術の方向性が変わるにつれて、特定のツール、フレームワーク、スタックにアイデンティティーの感覚を付けてはなりません。成長の著しい環境で成功するために最適な人材は、仕事に適したツールを学習して使用することに重点を置いています。したがって、学習と成長の機会を提供する準備ができていること。
-
あなたがそれを助けることができるならば、行列での管理を避けてください。 二重報告が解決するように見えるかもしれない問題に対処する他の方法があるかどうかを検討してください。
-
分散チームを受け入れる。 離れたメンバーと緊密なチームを構築することには課題はありませんが、そのメリットは多くあります。 Martin Fowler氏は、「チームを遠隔地にすることで、チームにもたらすことのできる人の範囲を広げることができます。 遠隔地のチームは、同一のチームが同じ場所にいる場合に比べて生産性が低いかもしれませんが、あなたが形成できる最高の共同チームよりも生産性が高いかもしれません。 、より強固なチーム全体を構築することができます。
組織が成長し成熟するにつれて、減速し、石灰化し、より保守的になる傾向があります。 継続的な改善を実践し、プラクティスを進化させることで、我々は負に陥らないようにし、時間をかけてより機敏で、実用的で、生産的に成長することができました。
3年間(そして多くの)の学習の成果がここにあります!
 カテゴリー :ベストプラクティス
カテゴリー :ベストプラクティス

