脅威の影響範囲は狂ったようなペースで拡大しています。毎日新しい脆弱性が露わになり、ITOps担当者が管理するサーバ、アプリケーション、およびエンドポイントの量は絶えず増加しています。最近の世界的なランサムウェア攻撃の脅威が数千ドルを加害者に稼がせていることで分かるように、これらの脅威はさらに強力になり頻発するようになっています。専門家は、犯罪者がしばしばデータ破壊の試みを隠す偽装をしていると考えています。
組織がより機敏になるようバイモーダルITOps(2つの流儀のITOps)の手法を採用するにつれて、インシデントを回避し、セキュリティを強化することはかなりの難題を引き起こす可能性があります。新しい課題には、コンテナとパブリッククラウドリソースを活用することと、これらの別々のデータドメイン間でセキュリティインシデントを管理すること、そして重要なリソースにアクセスできる新たな擬似管理ユーザーの集団を運用することが含まれます。ますます拡大するITOpsの要求に対して全層に渡る可視性とインシデント解決を可能にするには、SecOpsへの多面的な戦略が必要です。実際、SecOpsインシデント管理は、実用的で見やすい真に安全な環境を構築するために必要な組み合わせだという考えに私は傾いています。
フェーズ1:脅威を止める

まず第一に、SecOpsスタックの複雑さを軽減することが、SecOpsポリシーを実施するのに役立ちます。簡単に言えば、攻撃を阻止し、ITOpsチームに修復する必要があることを通知します。単純さは、セキュリティアラートやインシデントのノイズを削減し、本当に重要なシグナルに集中できるようにするためにに重要です。SecOpsのプラクティスでは、チームが組み込みのストップウォッチを活用して、可能な限り迅速に対応し、脅威がSLAや重要なデータに損害を与える前にそれを停止することを保証します。過酷な状況の好例は、ネットワークとシステムがゼロデイ攻撃やランサムウェアにさらされている場合です。このような場合、重要なのは、大規模な脅威への暴露を防止し、インシデント管理システムにアラートを発行するという戦略を構築することです。CryptolockerやCryptowallのような暗号化されたランサムウェアの場合、そのランサムウェアが脅威をもたらすのを防ぐツール(ソフォスのインフォグラフィックスの第2段階を参照)を利用して、ハンドシェイクを防ぎ、暗号の感染を回避することが目標です。
ファイアウォール、エンドポイント、第三者のセキュリティ監視ツール、およびその他の関連するデータソースを、中央のインシデント管理ソリューションにパイプすることができます。このように、SecOpsとITOpsには、優先度の高い問題の効果的な調査と修復に必要なデータとワークフローが即座に通知され、装備されます。効果的なセキュリティツールを使用することは、セキュリティインシデントの管理の成功に不可欠です。
フェーズ2:インシデント管理と修復
問題を検出して通知する能力だけでなく、事態の収れんや将来の予防策を十分に考えておくことは、ベストプラクティス、エンドツーエンドのセキュリティインシデントライフサイクル管理と同様に重要です。また、このフルスタックの可視性を実現するには、すべてのセキュリティシステムを集中的なインシデント管理ソリューションに統合して集約したいと思うでしょう。例えば、SNMPトラップ/クエリを活用して監視プラットフォームに情報を集約するようにファイアウォールやネットワークデバイスを構成します。さらにsyslogサーバーを統合し、すべてのセキュリティインシデントをこれらのソースに送信するようにします。

ファイアウォールとネットワークのsyslogを設定するときに、Info、Debugアラートと、Warning、Criticalアラートの間のしきい値を設定することで、かなりの時間を節約し、アラート疲れを軽減できます。ベンダーによって、しきい値が異ながす。 ただし、SNMPではOID(注:オブジェクトID)をフィルタリングしてInfo、Debugアラートを無視しWarning、Criticalアラートを許可することで、重要度の高いアラートのみをインシデント管理システムへ送信させるようにできます。
syslogを使用すると、より詳細なログ条件を設定できますが、ここで重要な点は、ノイズを抑えて特定の条件に合う場合にのみ通知させることです。これらのイベントを監視システムに集約できれば、実行可能な情報でアラートを強化したうえでチームに送信して脅威を修復するフレームワークを構築できます。
syslogは、いくつかの理由で価値あるものになります。監視システムに流入するセキュリティとネットワークデータに関する詳細な情報を取得するだけでなく、侵入検知と防御と脅威情報の収集も容易にすることができます。syslogを監視システムに直接つなぐのではなく、syslogデータをAlienVaultやLogRhythmなどのサードパーティの侵入解析システムに送信して侵入を容易に見つけられるようにしたり、ログデータを豊かにしたり、即応性の高いアラートを作成したりすることもできます。その後、PagerDutyなどのインシデント管理システムにアラートを送信して、関連のある症状をグループ化し、根本的な原因を理解し、適切なエキスパートにエスカレートし、適切なコンテキストで是正し、今後のセキュリティインシデント対応を改善するための分析や反省を実施できます。
-
結論:セキュリティツールを活用して脅威を実際に阻止する
-
ベースラインモニタリング:ベースラインのモニタリングおよびアラートポリシーを確立する
-
エンリッチメント:サードパーティのツールを活用してデータと脅威情報を強化にする
-
インシデント管理:フルスタックの可視性を最大化し、問題の優先順位付け、ルーティング、エスカレーションを保証します。ワークフローと分析で解決までの時間を短縮できます
最後に付け加えると、ハイブリッドクラウドやパブリッククラウドのリソースを使っている組織でも、同じフレームワークを実装できます。ただし可視化とアラート分析を強化するには、さまざまなサードパーティのツールを活用する必要があります。たとえば、Amazonクラウドを利用する際にはAWS Cloud Watchを活用して、あるいはMicrosoft Cloudを活用する際にはAzure Alertsを活用することで、パブリッククラウドサーバーの監視とアラートを使い、類似のしきい値の設定とノイズ削減が可能になります。さらに幸いなことに、Evident.ioやThreat Stackなどのサードパーティのツールもあり、アジャイル、パブリック、ハイブリッド、またはバイモーダルのITOps戦略を持つ誰もが、クラウドインフラストラクチャ全体にわたってセキュリティに焦点を当てた分析を簡単に実行できます。
SecOpsチームに合う完全なインシデント管理プロセスを設計する際に活用するツールやシステムは、シンプルさ、可視性、ノイズリダクション、実行可能性といった基本的な部分がその成功に最も重要な要素になります。ITOpsとSecOpsのチームはビジネス上に求められるものでは非常に似通った立場にいます。そこでは、2つのチームが絶え間なく増大するデバイス、サービス、およびその他のエンドポイントのリストに安全かつ効率的にアクセスする能力とビジネス上の要求がしばしば競合します。
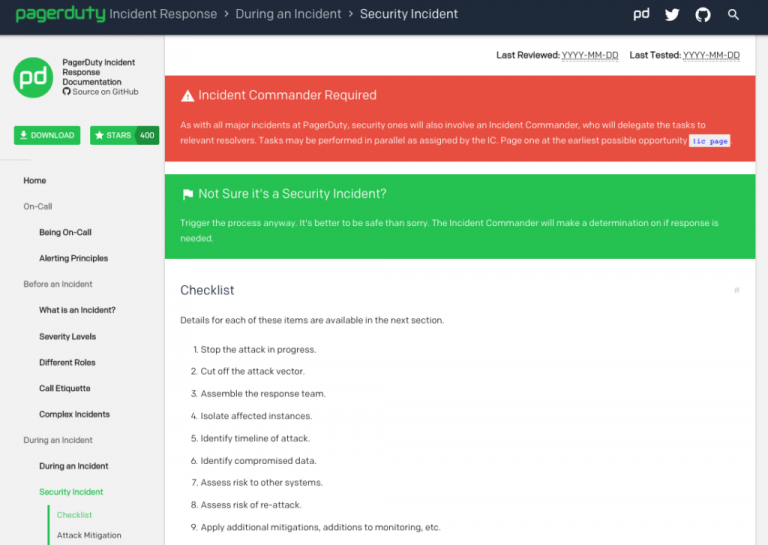
セキュリティインシデント対応のベストプラクティスの詳細をさらに知りたければ、我々が社内で使っているPagerDutyのオープンソースドキュメントを参照してください。実行可能なチェックリストと、攻撃方法を遮断する方法、レスポンスチームを組織する方法、侵入されたデータを処理する方法などの情報を得ることができます。これらのリソースが、効果的なインシデント管理を備えたSecOpsを最適化するための強固なフレームワークを構築する上での最初の出発点になることを願っています。
 カテゴリー :インシデント&アラート
カテゴリー :インシデント&アラート

